
Hadoop
Hadoop是什么
- hadoop是一个Aoache基金会所开发的分布式系统基础架构 。
- 主要解决,海量数据的存储和海量数据的分析计算问题。
- 广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
Hadoop发展史
Lucene
论文
GFS–>HDFS
Map-Reduce–>MR
BigTable–>HBase
Hadoop三大发行版本
Apache
最原始,最基本的版本,对于入门学习较好
Cloudera
在大型互联网企业中用的较多
Hortonworks
文档较好
Hadoop的优势(4高)
- 高可靠:Hadoop底层维护了多个数据副本,所以即使Hadoop某个计算或存储出现故障,也不会导致数据丢失。
- 高扩展性:在集群建分配任务数据,可方便的扩展数以千计的节点。
- 高效性:在Mao-Reduce 的思想下,Hadoop是并行工作的,以加快任务处理速度。
- 高容错性:能够自动将失败的任务重新分配。
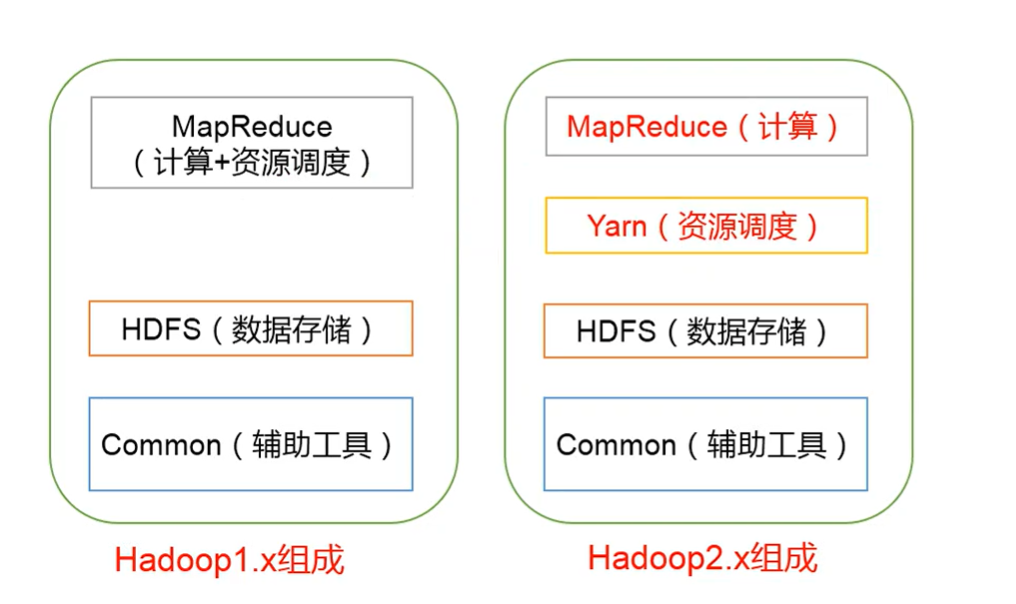
Hadoop组成
1.x 与2.x
HDFS架构概念
1.NameNode (nn)
存储额文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在的DataNode 等。
2.DataNode (dn)
在本地文件系统存储文件块数据,以及块数据的校验和。
3.Secondary NameNode (2nn)
用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
YARN 架构概念
ResourceManage(RM)主要作用
- 处理客户请求
- 监控NodeManage
- 启动或监控ApplicationMaster
- 资源的调度与分配
NodeManage(NM)主要作用
- 管理单个节点上的资源
- 处理来自ResourceManage的命令
- 处理来自ApplicationMaster的命令
ApplicationMaster(AM)主要作用
- 负责数据的切分
- 为应用程序申请资源并分配给内部的任务
- 任务的监控与容错
Container
- Container是YARN中的资源抽象,他封装了某个节点上的多维资源,如内存,CPU,磁盘,网络等。
MapReduce架构概述
MapReduce 将计算过程分为两个阶段:map 和 Reduce
- Map 阶段并行处理输入数据
- Reduce阶段对Map结果进行汇总
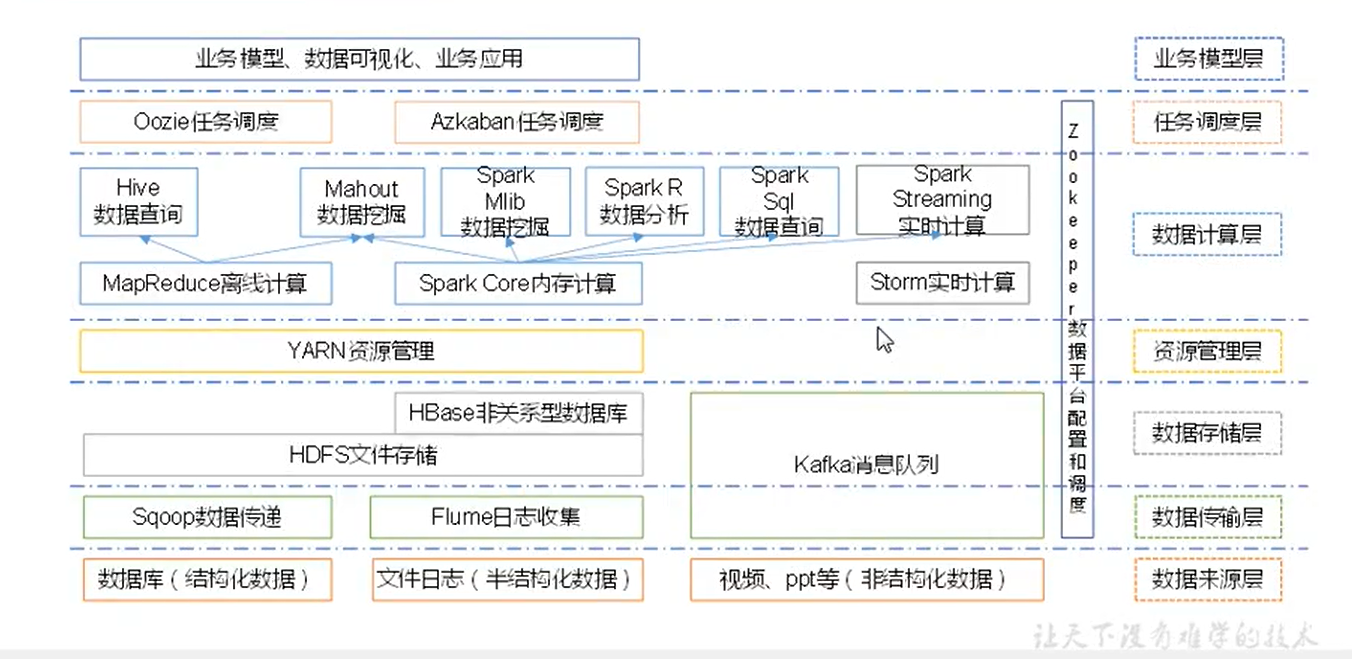
大数据计数生态体系
环境搭建
1.准备虚拟机
2.安装JDK
3.安装Hadoop
解压
配置环境变量
在
/etc/profile文件的最后加1
2
3export HADOOP_HOME=/usr/local/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin使用配置生效
1
$ source /ect/profile
4.Hadoop目录结构
bin
存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
etc
Hadoop的配置文件目录
lib
存放Hadoop的本地库(对数据进行压缩解压的功能)
sbin
存放启动或停止Hadoop相关服务的脚本
share
存放Hadoop的依赖jar包,文档,和官方案例。
5.Hadoop官网手册
Hadoop官方网站:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
Hadoop运行模式
Hadoop运行模式包括:
本地模式、伪分布式模式以及完全分布式模式。
本地运行模式
官方Grep案例
1.创建在hadoop-3.2.1文件下面创建一个input文件夹
1 | $ mkdir input |
2.将Hadoop的xml配置文件复制到input
1 | $ cp etc/hadoop/*.xml input |
3.执行share目录下的MapReduce程序
1 | $ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+' |
4.查看输出结果
1 | cat output/* |
官方WordCount案例
1.创建在hadoop-3.2.1文件下面创建一个wcinput文件夹
1 | mkdir wcinput |
2.在wcinput文件下创建一个wc.input文件
1 | $ cd wcinput |
3.编辑wc.input文件
1 | $ vim wc.input |
在文件中输入如下内容
1 | hadoopyarn |
保存退出::wq
4.回到Hadoop目录
5.执行程序
1 | $ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount wcinput wcoutput |
6.查看结果
1 | $ cat wcoutput /part-r-00000 |
1 | atguigu2 |
伪分布式运行模式
启动HDFS并运行MapReduce程序
1.分析
(1)配置集群
(2)启动、测试集群增、删、查
(3)执行WordCount案例
2.执行步骤
(1)配置集群
进入Hadoop的etc目录
1 | $ cd ./etc |
配置:hadoop-env.sh
Linux系统中获取JDK的安装路径:
1
$ echo $JAVA_HOME
1
/usr/local/jdk1.8.0_121
修改JAVA_HOME路径:
1
export JAVA_HOME=/usr/local/jdk1.8.0_121
配置:core-site.xml
1
2
3
4
5
6
7
8
9
10<!--指定HDFS中NameNode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!--指定Hadoop运行时产生文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.2.1/data/tmp</value>
</property>配置:hdfs-site.xml
1
2
3
4
5<!--指定HDFS副本的数量-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
(2)设置无密码SSH
现在检查您是否可以在不使用密码的情况下SSH到本地主机:
1
$ ssh localhost
如果没有密码就无法SSH到本地主机
请执行以下命令
1
2
3$ ssh-keygen -t rsa -P''-f〜/ .ssh / id_rsa
$ cat〜/ .ssh / id_rsa.pub >>〜/ .ssh / authorized_keys
$ chmod 0600〜/ .ssh / authorized_keys
(3)执行
格式化文件系统
1
$ bin/hdfs namenode -format
启动NameNode守护程序和DataNode守护程序:
1
$ ./sbin/start-dfs.sh
启动报错
1
2
3
4
5
6
7
8
9
10[root@iZ2zednzb8iugz3kgudq9bZ hadoop-3.2.1]# ./sbin/stop-dfs.sh
Stopping namenodes on [localhost]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Stopping datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Stopping secondary namenodes [iZ2zednzb8iugz3kgudq9bZ]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.添加以下配置到
hadoop-env.sh1
2
3HDFS_DATANODE_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root浏览Web界面以查找NameNode;默认情况下,它在以下位置可用:
1
http://localhost:9870/
设置执行MapReduce作业所需的HDFS目录:
1
2$ bin/hdfs dfs -mkdir /user/root
$ bin/hdfs dfs -mkdir /user/<用户名>- 创建多层目录
1
$ bin/hdfs dfs -mkdir -p /user/wry
- 查看多级目录
1
$ bin/hdfs dfs -ls -R /

将本地输入文件复制到分布式文件系统中:
1
2$ bin/hdfs dfs -mkdir -p /user/wry/input
$ bin/hdfs dfs -put etc/hadoop/*.xml /user/wry/input
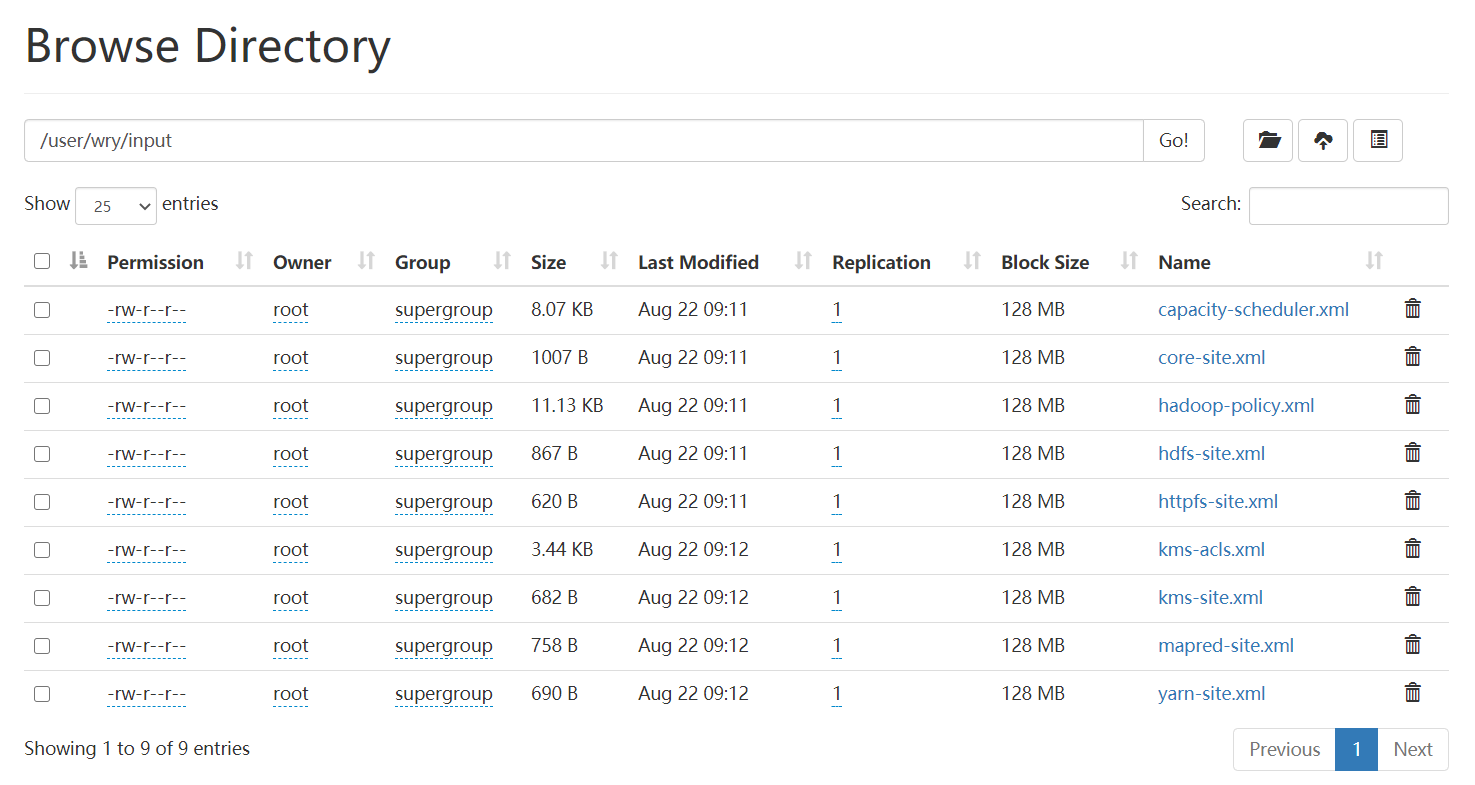
运行提供的一些示例:
1
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep /user/wry/input /user/wry/output 'dfs[a-z.]+'
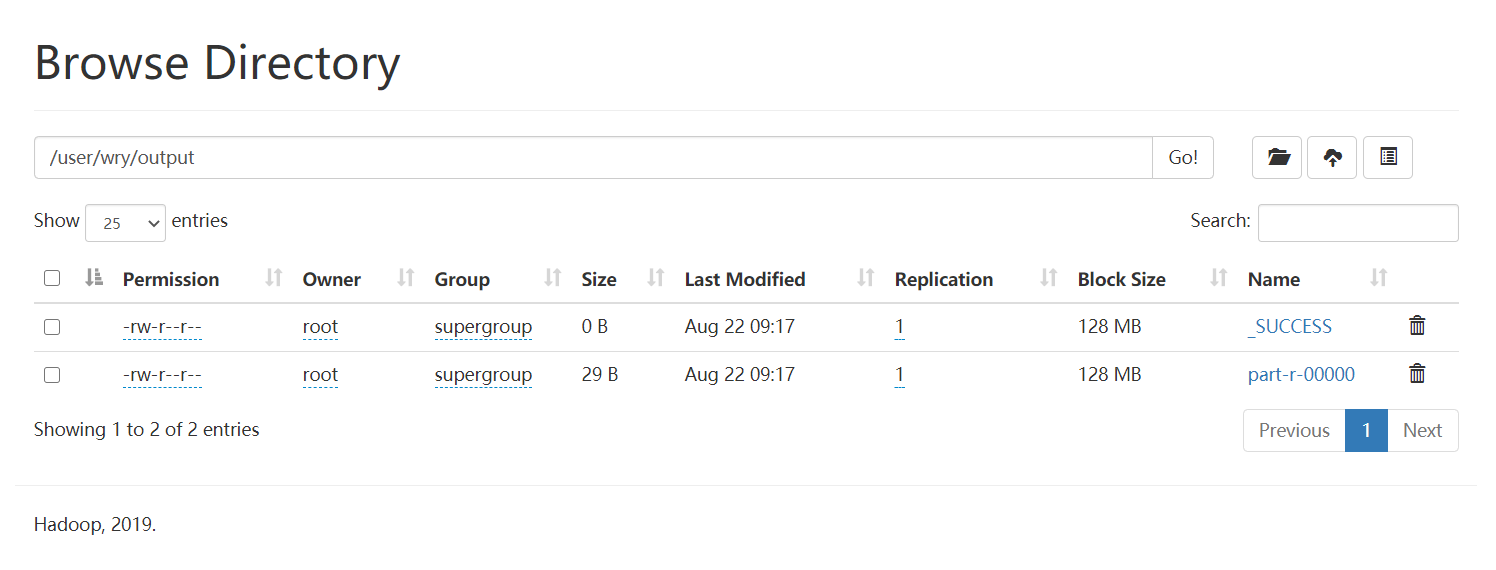
查看文件
1
$ bin/hdfs dfs -ls -r /user/wry/output
查看分布式文件系统上的输出文件:
1
$ bin/hdfs dfs -cat /user/wry/output/<文件名>
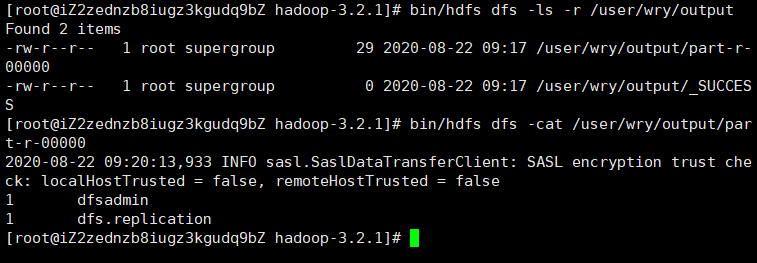
or
检查输出文件:将输出文件从分布式文件系统复制到本地文件系统并检查它们:
1
2$ bin/hdfs dfs -get /user/wry/output /usr/local/wryoutput
$ cat /usr/local/wryoutput/*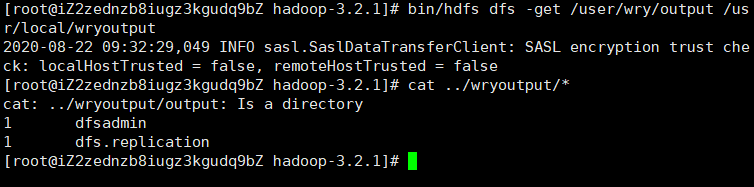
完成后,使用以下命令停止守护进程:
1
$ sbin/stop-dfs.sh
格式化NameNode 时要注意
1.先停止进程
2.删除data 、log文件
3.执行格式化命令
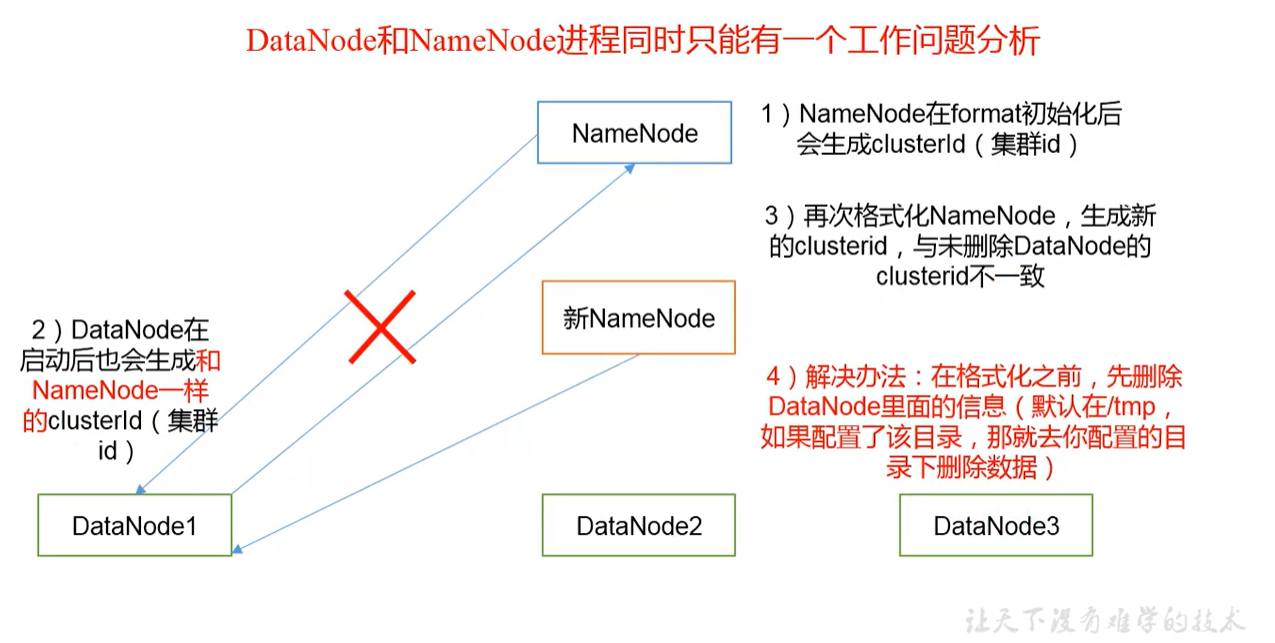
为什么不能一直 格式化NameNode
格式化NameNode,会产生新的集群Id,导致NameNode和DataNode的集群Id不一致,集群找不到以往的数据,所以,,格式化NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
启动YARN并运行MapReduce程序
1.分析
(1)配置集群在YARN上运行MR
(2)启动、测试集群增、删、查
(3)在YARN上执行WordCount案例
2.执行步骤
(1)配置集群
配置etc/hadoop/mapred-site.xml:
1 | <configuration> |
配置etc/hadoop/yarn-site.xml:
1 | <configuration> |
启动
1 | $ sbin/start-yarn.sh |
启动报错

配置etc/hadoop/hadoop-env.sh
1 | export YARN_RESOURCEMANAGER_USER=root |
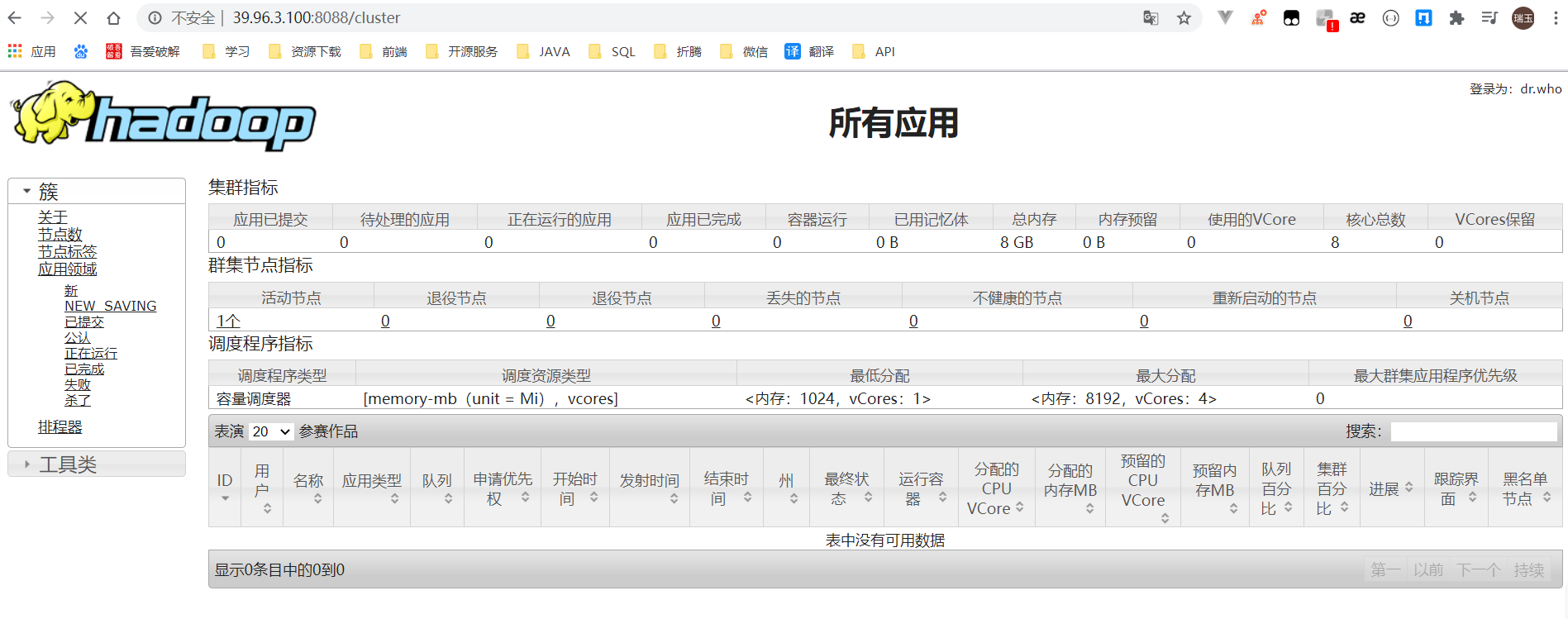
浏览ResourceManager的web界面;默认情况下,它位于:
ResourceManager - http://localhost:8088/
运行一个job
- 拷贝文件到hadoop 目录
1 | $ bin/hdfs dfs -put wcinput/wc.input /user/wry/wcinput |
- 运行
1 | $ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /user/wry/wcinput /user/wry/wcoutput |
- 查看
1 | $ bin/hadoop dfs -ls -r /user/wry/wcoutput |
配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
- 配置
etc/hadoop/mapred-site.xml
1 | <!--历史服务器端地址--> |
启动历史服务器
1
$ sbin/mr-jobhistory-daemon.sh starthistoryserver
查看历史服务器是否启动
1
$ jps
查看JobHistory
JobHistory - http://hadoop101:19888/jobhistory
配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager、ResourceManager和
HistoryManager。
开启日志聚集功能具体步骤如下:
配置
etc/hadoop/yarn-site.xml1
2
3
4
5
6
7
8
9
10<!--日志聚集功能使能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--日志保留时间设置7天-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>关闭NodeManager、ResourceManager和HistoryManager
- 关闭所有 包括 NodeManager、ResourceManager、Name Node、DataNode
1
$ sbin/stop-all.sh
- 关闭 NodeManager、ResourceManager
1
$ sbin/stop-yarn.sh
- 关闭 Name Node、DataNode
1
$ sbin/stop-dfs.sh
- 关闭 HistoryManager
1
$ sbin/mr-jobhistory-daemon.sh stop historyserver
启动NodeManager、ResourceManager和HistoryManager
删除HDFS上已经存在的输出文件
1
$ bin/hadoop dfs -rm -f -r /user/wry/wcoutput
执行WordCount程序
1
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /user/wry/wcinput /user/wry/wcoutput
查看日志,如图所示
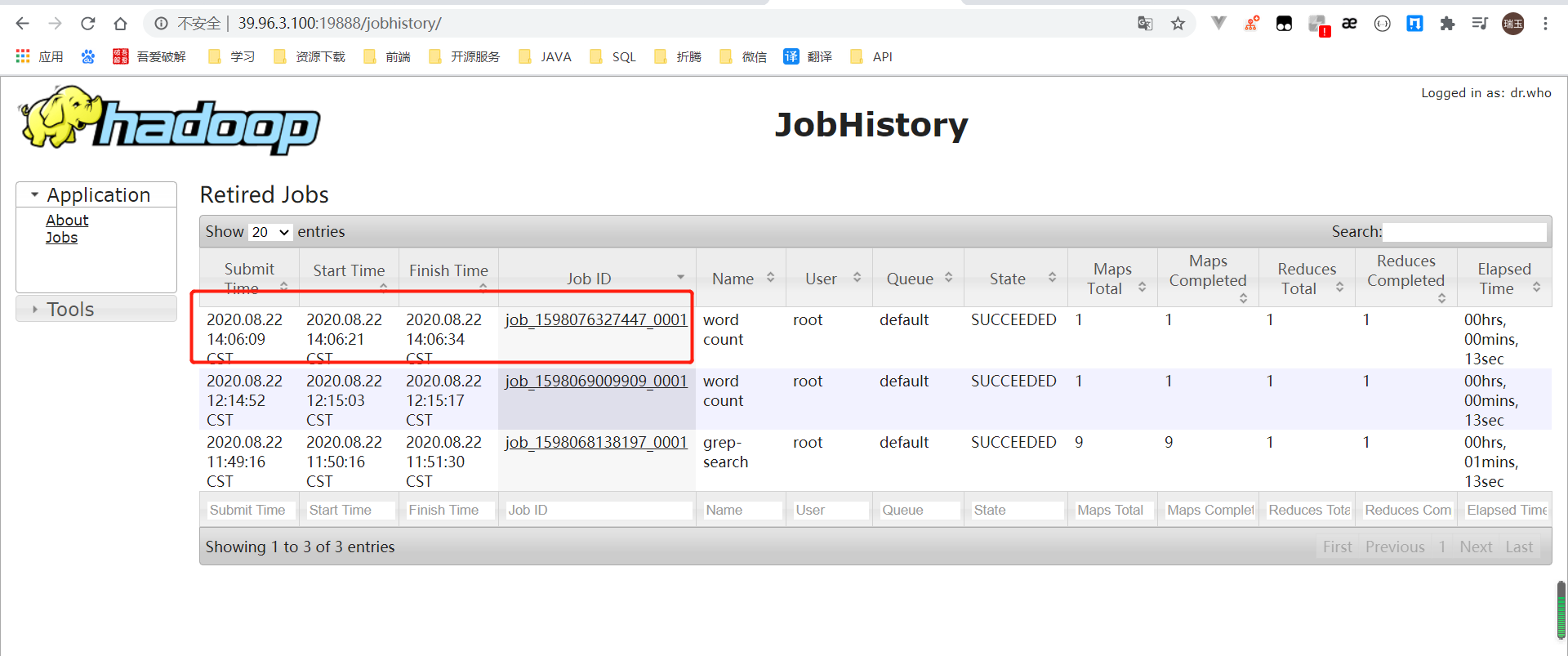
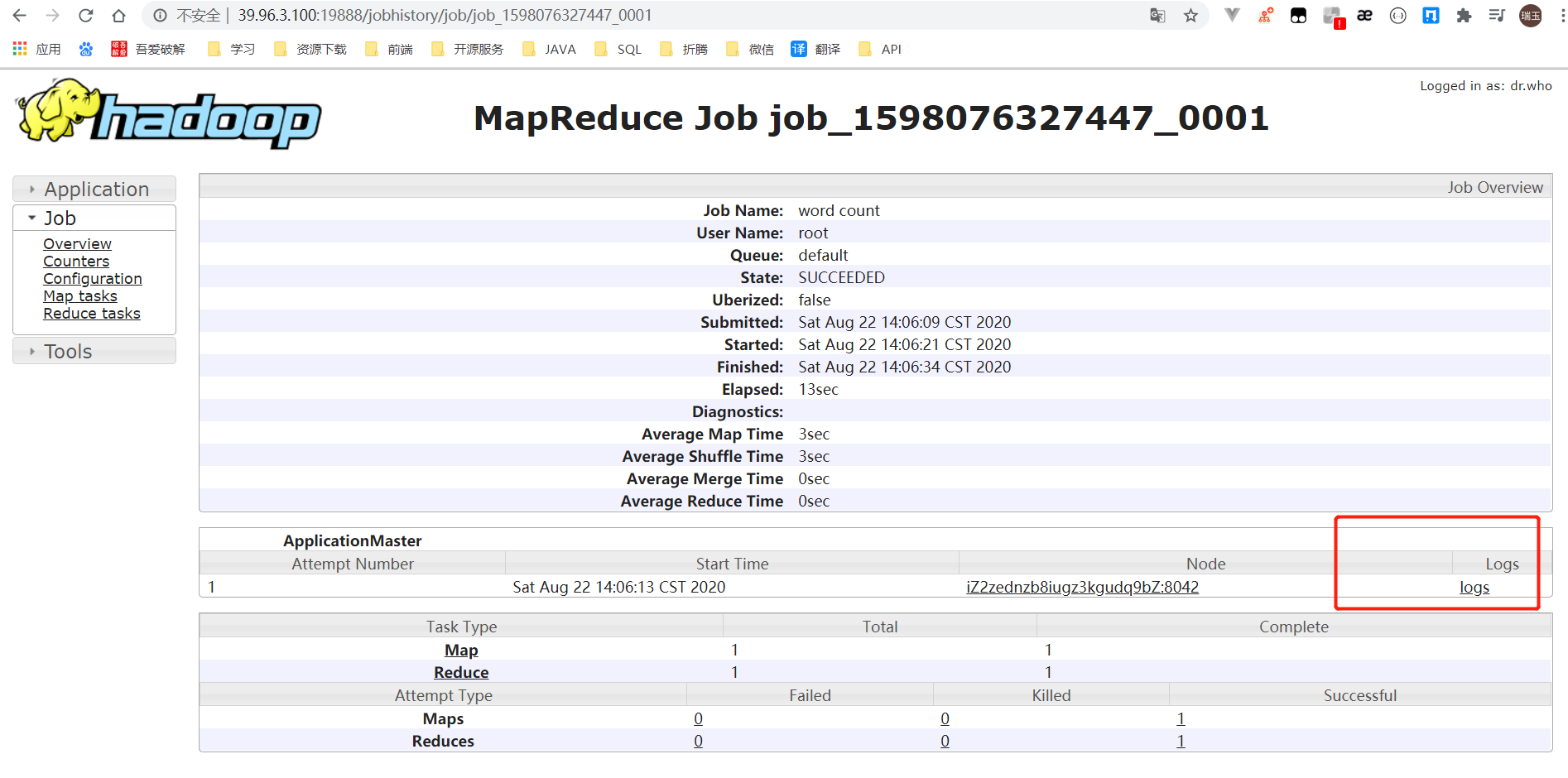
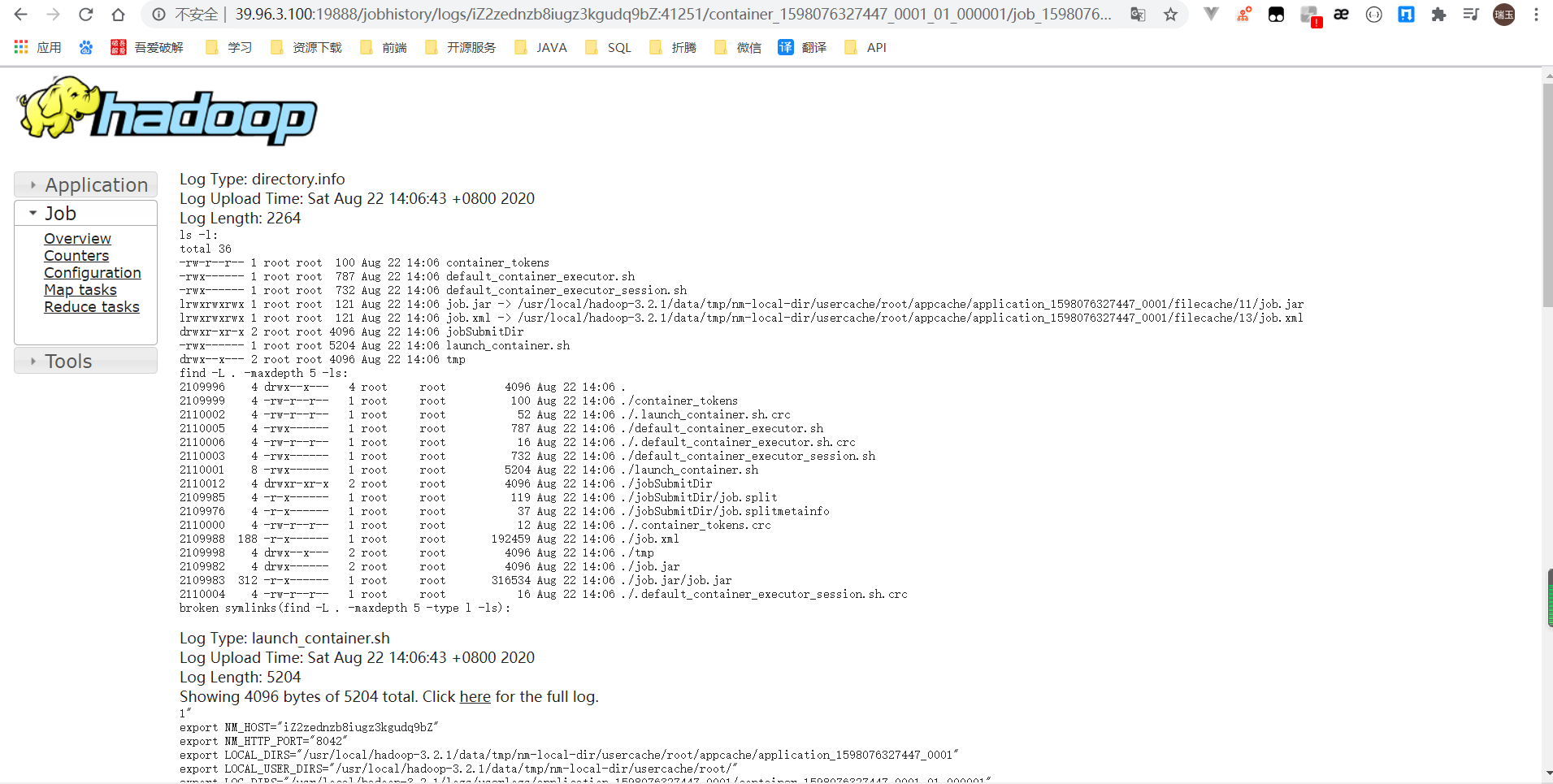
配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认
配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件:
要获取的默认文件文件存放在Hadoop的jar包中的位置
| 配置文件名称 | 默认配置所在的文件路径 |
|---|---|
| core-default.xml | hadoop-common-2.7.2.jar/core-default.xml |
| hdfs-default.xml | hadoop-hdfs-2.7.2.jar/hdfs-default.xml |
| yarn-default.xml | hadoop-yarn-common-2.7.2.jar/yarn-default.xml |
| mapred-default.xml | hadoop-mapreduce-client-core-2.7.2.jar/mapred-default.xml |
(2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在
$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
完全分布式运行模式(开发重点)
分析
1)准备3台客户机(关闭防火墙、静态ip、主机名称)
2)安装JDK
3)配置环境变量
4)安装Hadoop
5)配置环境变量
6)配置集群
7)单点启动
8)配置ssh
9)群起并测试集群
虚拟机准备
(1)改IP地址
1 | $ vim /etc/sysconfig/network-scripts/ifcfg-ens33 |
1 | TYPE=Ethernet |
(2)改主机名
不配置后期的数据节点可能会找不到。
1 | $ vim /etc/hotos |
1 | 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 |
编写集群分发脚本xsync
1.scp(securecopy)安全拷贝
(1)scp定义:
scp可以实现服务器与服务器之间的数据拷贝。(fromserver1toserver2)
(2)基本语法
1 | scp -r $pdir/$fname $user@hadoop$host:$pdir/$fname |
(3)案例实操
(a)在192.168.100.101上,将192.168.100.101中/usr/local/software目录下的软件拷贝到192.168.100.102上。
1 | $ scp -r /usr/local/software/* [email protected]:/usr/local/software |
(b)在192.168.100.103上,将192.168.100.101服务器上的/usr/local/software目录下的软件拷贝到192.168.100.103上。
1 | $ scp -r [email protected]:/usr/local/software/* /usr/local/software/ |
(c)在192.168.100.103上操作将192.168.100.101中/usr/local/software目录下的软件拷贝到192.168.100.104上。
1 | $ scp -r [email protected]:/usr/local/software/* [email protected]:/usr/local/software/ |
2.rsync远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:
用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
(1)基本语法
1 | rsync -rvl $pdir/$fname $user@hadoop$host:$pdir/$fname |
选项参数说明
| 选项 | 功能 |
|---|---|
| -r | 递归 |
| -v | 显示复制过程 |
| -l | 拷贝符号连接 |
(2)案例实操
(a)把192.168.100.101机器上的/usr/local/software目录同步到192.168.100.102服务器的root用户
下的/usr/local/software目录
1 | $ rsync -rvl /usr/local/software/* [email protected]:/usr/local/software/ |
3.xsync集群分发脚本
(1)需求
循环复制文件到所有节点的相同目录下
(2)需求分析
(a)rsync命令原始拷贝:
1 | rsync -rvl /usr/local/program/* [email protected]:/usr/local/program/ |
(b)期望脚本:
xsync要同步的文件名称
(c)说明:在/home/<用户名>/bin这个目录下存放的脚本,root用户可以在系统任何地方直接执行。
(3)脚本实现
(a)在/home/<用户名>/bin目录下创建bin目录,并在bin目录下xsync创建文件,文件内容如下:
1 | $ cd /home/<用户名> |
1 |
|
(b)修改脚本xsync具有执行权限
1 | $ chmod 777 xsync |
(c)调用脚本形式:xsync文件名称
1 | $ xsync /home/<用户名>/bin |
注意:
如果将
xsync放到/home/<用户名>/bin目录下仍然不能实现全局使用,可以将
xsync移动到/usr/local/bin目录下。
集群配置
1.集群部署规化
| 192.168.100.102 -hadoop102 | 192.168.100.103-hadoop103 | 192.168.100.104-hadoop104 | |
|---|---|---|---|
| HDFS | NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN | NodeManage |
ResourceManage NodeManage |
NodeManage |
机器改IP
2.配置集群
(1)核心配置文件
在192.168.100.102 上
配置etc/hadoop/core-site.xml
1 | $ cd /usr/local/program/hadoop3.2.1 |
在该文件中编写如下配置
1 | <!--指定HDFS中NameNode的地址--> |
(2)HDFS配置文件
配置etc/hadoop/hadoop-env.sh
1 | export JAVA_HOME=/usr/local/program/jdk1.8 |
配置etc/hadoop/hdfs-site.xml
1 | <property> |
(3)YARN配置文件
一般在 shell中输入
1 | $ hadoop classpath |
然后 这些输出 直接 粘贴到 yarn 的配置文件里 yarn-site.xml的属性
配置etc/hadoop/hadoop-env.sh
1 | export YARN_RESOURCEMANAGER_USER=root |
配置etc/hadoop/yarn-site.xml
1 | <!--用于指定执行MapReduce作业的运行时框架。可以是local、classic 或yarn之一 --> |
(4)MapReduce配置文件
配置etc/hadoop/mapred-site.xml
1 | <!--指定MR运行在Yarn上--> |
3.在集群上分发配置好的Hadoop配置文件
1 | $ xsync ./etc/hadoop/ |
4.查看文件分发情况
集群单点启动
(1)如果集群是第一次启动,需要格式化NameNode
1 | $ bin/hdfs namenode -formart |
(2)在192.168.100.102上启动NameNode
1 | $ sbin/hadoop-daemon.sh start namenode |
(3)在192.168.100.102,192.168.100.103以及192.168.100.104上分别启动DataNode
1 | $ sbin/hadoop-daemon.sh start datanode |
(4)思考:每次都一个一个节点启动,如果节点数增加到1000个怎么办?
早上来了开始一个一个节点启动,到晚上下班刚好完成,下班?
SSH无密登录配置
1.配置ssh
(1)基本语法
ssh另一台电脑的ip地址
(2)ssh连接时出现Hostkeyverificationfailed的解决方法
1 | $ ssh 192.168.1.103 |
(3)解决方案如下:直接输入yes
2.无密钥配置
(1)免密登录原理
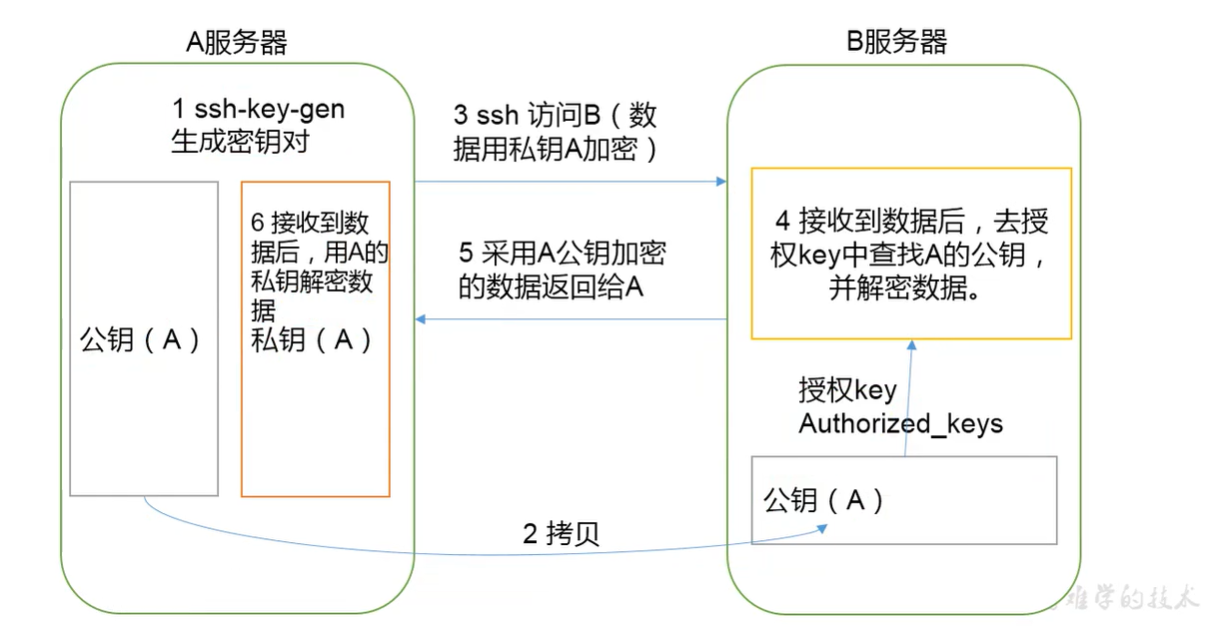
(2)192.168.100.102生成公钥和私钥:
1 | $ cd /root/.ssh |
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(3)将公钥拷贝到要免密登录的目标机器上
1 | $ ssh-copy-id 192.168.100.102 |
(4)192.168.100.103生成公钥和私钥,进行公钥拷贝到要免密登录的目标机器上
3..ssh文件夹下(~/.ssh)的文件功能解释
| known_hosts | 记录ssh访问过计算机的公钥(publickey) |
|---|---|
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过得无密登录服务器公钥 |
群起集群
1.配置etc/hadoop/workers
1 | $ vim etc/hadoop/workers |
添加以下节点
1 | 192.168.100.102 |
注意:
千万不要有多余的空格
2.启动集群
(1)如果集群是第一次启动
需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
1 | $ bin/hdfs namenode -format |
(2)启动HDFS
1 | $ sbin/start-dfs.sh |
jps查看是否启动
(3)启动YARN
1 | $ sbin/start-yarn.sh |
(3)Web端查看SecondaryNameNode
1 | http://192.168.100.102:9870/ |
(4)查看文件系统的基本数据
1 | $ bin/hdfs dfsadmin -report |
注意:
NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动YARN,应该在ResouceManager所在的机器上启动YARN。
3.集群基本测试
(1)上传文件到集群
1 | $ bin/hdfs dfs -put ./wcinput/wc.input /user/wry/input |
(2)上传文件后查看文件存放在什么位置
1 | $ pwd |
1 | /usr/local/program/hadoop-3.2.1/data/tmp/hadoop-root/dfs/data/current/BP-719430212-127.0.0.1-1598525636602/current/finalized/subdir0/subdir0 |
集群启动/停止方式总结
1.各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
1 | $ sbin/hadoop-daemon.sh start/stop namenode/datanode/secondarynamenode |
(2)启动/停止YARN
1 | $ sbin/yarn-daemon.sh start/stop resourcemanager/nodemanager |
2.各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
1 | $ sbin/start-dfs.sh/stop-dfs.sh |
(2)整体启动/停止YARN
1 | $ sbin/start-yarn.sh/stop-yarn.sh |
crontab定时任务设置
基本语法
crontab [选项]
选项说明
| 选项 | 功能 |
|---|---|
| -e | 编辑crontab 定时任务 |
| -l | 查询crontab任务 |
| -r | 删除当前用户所有的crontab 任务 |
参数说明
1 | $ crontab -e |
(1)进入crontab编辑界面。会打开vim 编辑你的工作
1 | * * * * * 执行的任务 |
| 项目 | 含义 | 范围 |
|---|---|---|
| 第一个“*” | 一小时当中的第几分钟 | 0-59 |
| 第二个“*” | 一天当中的第几小时 | 0-23 |
| 第三个“*” | 一月当中的第几天 | 1-31 |
| 第四个“*” | 一年当中的第几月 | 1-12 |
| 第五个“*” | 一周当中的星期几 | 0-7(0和7都代表星期日) |
(2)特殊符合
| 特殊符合 | 含义 |
|---|---|
| * | 代表任何时间。比如第一个“*”,就代表一小时中的每分钟都有执行一次 |
| , | 代表不连需的时间。比如”0 8,12,16 * * *” 命令,就代表在每天的8点0分,12点0分,16点0分都执行一次 |
| - | 代表连续的时间范围。比如”0 5 * * 1-6” ,就代表在周一到周六的凌晨5点0分执行命令 |
| */n | 代表每个多久执行一次。比如”*/10 * * * *”,就代表没10分钟执行一次命令 |
(3)特殊特定时间执行命令
| 时间 | 含义 |
|---|---|
| 45 22 * * * | 在22点45 分执行命令 |
| 0 17 * * 1 | 每周一的17点0分执行命令 |
| 0 5 1,15 * * | 每月1号和15号的凌晨5点0分执行命令 |
| 40 4 * * 1-5 | 每周一到周五的凌晨4点40 分执行命令 |
| */10 4 * * * | 每天的凌晨4点,没隔10分钟执行一次命令 |
| 0 0 1,15 * 1 | 每月1号和15号,每周一的0点0分都会执行命令。注意:星期几和几号最好不要同时出现,因为他们定义的都是天。 |
(4)案例实操
每隔1分钟,向
/root/bailongma.txt文件中添加一个11 的数字。1
*/1 * * * * /bin/echo "11" >>/root/bailongma.txt
集群时间同步
时间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间。

Linux
配置静态IP
第一步:修改VMnet配置
在VMware里,依次点击”编辑“ - ”虚拟网络编辑器“,如下图,我选择的是NAT模式: 以下VMnet2为配置

其中子网ip随便写,子网掩码自己计算,如果不太熟悉就完全配置和我一样就行
A类默认的子网掩码:255.0.0.0
B类默认的子网掩码:255.255.0.0
C类默认的子网掩码:255.255.255.0
为了使用静态IP将: 使用本地DHCP服务将IP地址分配给虚拟机 取消(默认是选择状态)
点击NAT设置
将网关ip记住如下图,最后配置虚拟机ip文件所用
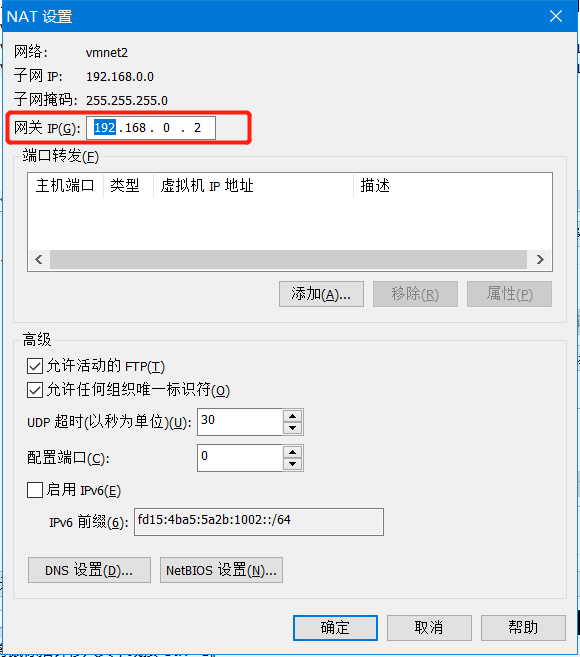
第二步:进入虚拟机
以root权限登陆centos8并编辑vi /etc/sysconfig/network-scripts/ifcfg-ens33这个文件,效果如下:
1 | TYPE=Ethernet |
然后 :wq保存退出
第三步: 刷新网卡配置
CentOS 8 使用 : nmcli c reload
CentOS7 使用 /etc/init.d/network restart
如果不能上网直接使用reboot 命令重启
关闭防火墙
centos8
永久关闭防火墙
1 | $ systemctl disable firewalld |
查看防火墙
1 | $ systemctl status firewalld.service |
停止防火墙
1 | $ systemctl stop firewalld.service |
启用防火墙
1 | $ systemctl start firewalld.service |
配置JDK
第一步:解压
1 | $ tar -zxvf /usr/local/software/jdk1.8.231 -C /usr/local/program/ |
第二步:配置环境变量
1 | $ vim /etc/profile |
在最后添加java 环境配置
1 | export JAVA_HOME=/usr/local/program/jdk1.8.231 |
第三步:使配置生效
1 | $ source /etc/profile |
配置SSH连接
第一步:修改配置
1 | $ vim /etc/ssh/sshd_config |
打开 注释修改以下配置
ClientAliveInterval 60
表示每分钟发送一次, 然后客户端响应, 这样就保持长连接了
ClientAliveCountMax 3
ClientAliveCountMax表示服务器发出请求后客户端没有响应的次数达到一定值, 就自动断开
第二步:重启服务
1 | $ service sshd restart |
1 | tar -zxvf /usr/local/software/hadoop-3.2.1.tar.gz -C /usr/local/program/ |